
Java对象序列化(整理篇)
在网上看了很多有关序列化的文章,我自己也写了两篇,现在感觉这些文章都没有很好的把序列化说清楚(包括我自己在内),所以在此我将总结前人以及自己的经验,用更浅显易懂的语
在网上看了很多有关序列化的文章,我自己也写了两篇,现在感觉这些文章都没有很好的把序列化说清楚(包括我自己在内),所以在此我将总结前人以及自己的经验,用更浅显易懂的语言来描述该机制,当然,仍然会有不好的地方,希望你看后可以指出,作为一名程序员应该具有不断探索的精神和强烈的求知欲望!
序列化概述:
简单来说序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化,流的概念这里不用多说(就是I/O),我们可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间(注:要想将对象传输于网络必须进行流化)!在对对象流进行读写操作时会引发一些问题,而序列化机制正是用来解决这些问题的!
问题的引出:
如上所述,读写对象会有什么问题呢?比如:我要将对象写入一个磁盘文件而后再将其读出来会有什么问题吗?别急,其中一个最大的问题就是对象引用!举个例子来说:假如我有两个类,分别是A和B,B类中含有一个指向A类对象的引用,现在我们对两个类进行实例化{ A a = new A(); B b = new B(); },这时在内存中实际上分配了两个空间,一个存储对象a,一个存储对象b,接下来我们想将它们写入到磁盘的一个文件中去,就在写入文件时出现了问题!因为对象b包含对对象a的引用,所以系统会自动的将a的数据复制一份到b中,这样的话当我们从文件中恢复对象时(也就是重新加载到内存中)时,内存分配了三个空间,而对象a同时在内存中存在两份,想一想后果吧,假如我想修改对象a的数据的话,那不是还要搜索它的每一份拷贝来达到对象数据的一致性,这不是我们所希望的!
以下序列化机制的解决方案:
1.保存到磁盘的所有对象都获得一个序列号(1, 2, 3等等)
2.当要保存一个对象时,先检查该对象是否被保存了。
3.假如以前保存过,只需写入"与已经保存的具有序列号x的对象相同"的标记,否则,保存该对象
通过以上的步骤序列化机制解决了对象引用的问题!
序列化的实现:
将需要被序列化的类实现Serializable接口,该接口没有需要实现的方法,implements Serializable只是为了标注该对象是可被序列化的,然后使用一个输出流(如:FileOutputStream)来构造一个ObjectOutputStream(对象流)对象,接着,使用ObjectOutputStream对象的writeObject(Object obj)方法就可以将参数为obj的对象写出(即保存其状态),要恢复的话则用输入流。
例子:
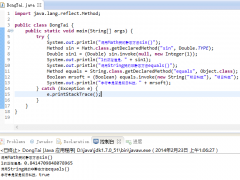
import Java.io.*;
public class Test
{
public static void main(String[] args)
{
Employee harry = new Employee("Harry Hacker", 50000);
Manager manager1 = new Manager("Tony Tester", 80000);
manager1.setSecretary(harry);
Employee[] staff = new Employee[2];
staff[0] = harry;
staff[1] = manager1;
try
{
ObjectOutputStream out = new ObjectOutputStream(
new FileOutputStream("employee.dat"));
out.writeObject(staff);
out.close();
ObjectInputStream in = new ObjectInputStream(
new FileInputStream("employee.dat"));
Employee[] newStaff = (Employee[])in.readObject();
in.close();
/**
*通过harry对象来加薪
*将在secretary上反映出来
*/
newStaff[0].raiseSalary(10);
for (int i = 0; i < newStaff.length; i++)
System.out.println(newStaff[i]);
}
catch (Exception e)
{
e.printStackTrace();
}
}
}
class Employee implements Serializable
{
public Employee(String n, double s)
{
name = n;
salary = s;
}
/**
*加薪水
*/
public void raiseSalary(double byPercent)
{
double raise = salary * byPercent / 100;
salary += raise;
}
public String toString()
{
return getClass().getName()
+ "[name = "+ name
+ ",salary = "+ salary
+ "]";
}
private String name;
private double salary;
}
class Manager extends Employee
{
public Manager(String n, double s)
{
super(n, s);
secretary = null;
}
/**
*设置秘书
*/
public void setSecretary(Employee s)
{
secretary = s;
}
public String toString()
{
return super.toString()
+ "[secretary = "+ secretary
+ "]";
}
//secretary代表秘书
private Employee secretary;
}
修改默认的序列化机制:
在序列化的过程中,有些数据字段我们不想将其序列化,对于此类字段我们只需要在定义时给它加上transient要害字即可,对于transient字段序列化机制会跳过不会将其写入文件,当然也不可被恢复。
精彩图集

精彩文章