Java虚拟机JVM性能优化(三):垃圾收集详解(2)
传统的复制垃圾收集器使用堆中的两个地址空间(即from空间和to空间),当执行垃圾收集时from空间的活动对象被复制到to空间,当from空间的所有活动对象都被移出(译者注:复制到to空间或者老年代)后,就可以回收整个from空间了,当再次开始分配空间时将首先使用to空间(译者注:即上一轮的to空间作为新一轮的from空间)。
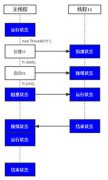
在该算法的早期实现中,from空间和to空间不断变换位置,也就是说当to空间满了,触发了垃圾收集,to空间就成为了from空间,如图1所示。

图1 传统的复制垃圾收集顺序
最新的复制算法允许堆内任意地址空间作为to空间和from空间。这样它们不需要彼此交换位置,而只是逻辑上变换了位置。
复制收集器的优点是在to空间被复制的对象紧凑排列,完全没有碎片。而碎片化正是其他垃圾收集器所面临的一个共同问题,也是我之后主要讨论的问题。
复制收集器的缺陷
通常来说复制收集器是stop-the-world的,也就是说只要垃圾收集在进行,应用程序就无法执行。对于这种实现来说,你需要复制的东西越多,对应用程序性能的影响就越大。对于那些响应时间敏感的应用来说这是个缺点。使用复制收集器时,你还要考虑最坏的场景(即from空间中的所有对象都是活动对象),这时你需要为移动这些活动对象准备足够大的空间,因此to空间必须大到可以装下from空间的所有对象。由于这个限制,复制算法的内存利用率稍有不足(译者注:在最坏的情况下to空间需要和from空间大小相同,所以只有50%的利用率)。
标记-清除收集器
部署在企业生产环境上的大多数商业JVM采用的都是标记-清除(或者叫标记)收集器,因为它没有复制垃圾收集器对应用程序性能的影响问题。其中最有名的标记收集器包括CMS、G1、GenPar和DeterministicGC。
标记-清除收集器跟踪对象引用,并且用标志位将每个找到的对象标记为live。这个标志位通常对应堆上的一个地址或是一组地址。例如:活动位可以是对象头的一个位(译者注:bit)或是一个位向量、一个位图。
在标记完成之后就进入了清除阶段。清除阶段通常都会再次遍历堆(不仅是标记为live的对象,而是整个堆),用来定位那些没有标记的连续内存地址空间(没有被标记的内存就是空闲并可回收的),然后收集器将它们整理为空闲列表。垃圾收集器可以有多个空闲列表(通常按照内存块的大小划分),有些JVM(例如:JRockit Real Time)的收集器甚至基于应用程序的性能分析和对象大小的统计结果来动态划分空闲列表。
清除阶段过后,应用程序就可以再次分配内存了。从空闲列表中为新对象分配内存时,新分配的内存块需要符合新对象的大小,或是线程的平均对象大小,或是应用程序的TLAB大小。为新对象找到大小合适的内存块有助于优化内存和减少碎片。
标记-清除收集器的缺陷
标记阶段的执行时间依赖于堆中活动对象的数量,而清除阶段的执行时间依赖于堆的大小。因此对于堆设置较大并且堆中活动对象较多的情况,标记-清除算法会有一定的暂停时间。
对于内存消耗很大的应用程序来说,你可以调整垃圾收集参数以适应各种应用程序的场景和需要。在很多情况下,这种调整至少推迟了标记阶段/清除阶段给应用程序或服务协议SLA(SLA这里指应用程序要达到的响应时间)带来的风险。但是调优仅仅对特定的负载和内存分配率有效,负载变化或是应用程序本身的修改都需要重新调优。
标记-清除收集器的实现
至少有两种已经在商业上验证的方法来实现标记-清除垃圾收集。一种是并行垃圾收集,另一种是并发(或者多数时间是并发)垃圾收集。
并行收集器
并行收集是指资源被垃圾收集线程并行使用。大多数并行收集的商业实现都是stop-the-world收集器,即所有的应用程序线程都暂停直到完成一次垃圾收集,因为垃圾收集器可以高效地使用资源,所以通常会在吞吐量的基准测试中得到高分,如SPECjbb。如果吞吐量对你的应用程序至关重要,那么并行垃圾收集器是一个很好的选择。
- 上一篇:浅析java创建文件和目录
- 下一篇:Java虚拟机JVM性能优化(二):编译器