零基础写python爬虫之urllib2使用指南(2)
import urllib2
import cookielib
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
response = opener.open('http://www.baidu.com')
for item in cookie:
print 'Name = '+item.name
print 'Value = '+item.value
运行之后就会输出访问百度的Cookie值:

6.使用 HTTP 的 PUT 和 DELETE 方法
urllib2 只支持 HTTP 的 GET 和 POST 方法,如果要使用 HTTP PUT 和 DELETE ,只能使用比较低层的 httplib 库。虽然如此,我们还是能通过下面的方式,使 urllib2 能够发出 PUT 或DELETE 的请求:
import urllib2
request = urllib2.Request(uri, data=data)
request.get_method = lambda: 'PUT' # or 'DELETE'
response = urllib2.urlopen(request)
7.得到 HTTP 的返回码
对于 200 OK 来说,只要使用 urlopen 返回的 response 对象的 getcode() 方法就可以得到 HTTP 的返回码。但对其它返回码来说,urlopen 会抛出异常。这时候,就要检查异常对象的 code 属性了:
import urllib2
try:
response = urllib2.urlopen('http://bbs.csdn.net/why')
except urllib2.HTTPError, e:
print e.code
8.Debug Log
使用 urllib2 时,可以通过下面的方法把 debug Log 打开,这样收发包的内容就会在屏幕上打印出来,方便调试,有时可以省去抓包的工作
import urllib2
httpHandler = urllib2.HTTPHandler(debuglevel=1)
httpsHandler = urllib2.HTTPSHandler(debuglevel=1)
opener = urllib2.build_opener(httpHandler, httpsHandler)
urllib2.install_opener(opener)
response = urllib2.urlopen('http://www.google.com')
这样就可以看到传输的数据包内容了:
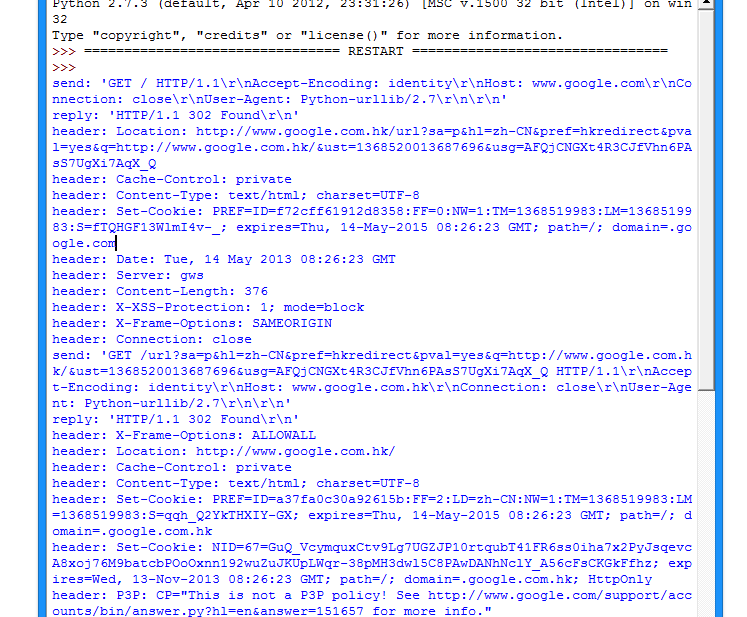
9.表单的处理
登录必要填表,表单怎么填?
首先利用工具截取所要填表的内容。
比如我一般用firefox+httpfox插件来看看自己到底发送了些什么包。
以verycd为例,先找到自己发的POST请求,以及POST表单项。
可以看到verycd的话需要填username,password,continueURI,fk,login_submit这几项,其中fk是随机生成的(其实不太随机,看上去像是把epoch时间经过简单的编码生成的),需要从网页获取,也就是说得先访问一次网页,用正则表达式等工具截取返回数据中的fk项。continueURI顾名思义可以随便写,login_submit是固定的,这从源码可以看出。还有username,password那就很显然了:
# -*- coding: utf-8 -*-
import urllib
import urllib2
postdata=urllib.urlencode({
'username':'汪小光',
'password':'why888',
'continueURI':'http://www.verycd.com/',
'fk':'',
'login_submit':'登录'
})
req = urllib2.Request(
url = 'http://secure.verycd.com/signin',
data = postdata
)
result = urllib2.urlopen(req)
print result.read()
10.伪装成浏览器访问
某些网站反感爬虫的到访,于是对爬虫一律拒绝请求
这时候我们需要伪装成浏览器,这可以通过修改http包中的header来实现