零基础写python爬虫之使用Scrapy框架编写爬虫(3)
3.2取
爬取整个网页完毕,接下来的就是的取过程了。
光存储一整个网页还是不够用的。
在基础的爬虫里,这一步可以用正则表达式来抓。
在Scrapy里,使用一种叫做 XPath selectors的机制,它基于 XPath表达式。
如果你想了解更多selectors和其他机制你可以查阅资料:点我点我
这是一些XPath表达式的例子和他们的含义
/html/head/title: 选择HTML文档<head>元素下面的<title> 标签。
/html/head/title/text(): 选择前面提到的<title> 元素下面的文本内容
//td: 选择所有 <td> 元素
//div[@class="mine"]: 选择所有包含 class="mine" 属性的div 标签元素
以上只是几个使用XPath的简单例子,但是实际上XPath非常强大。
可以参照W3C教程:点我点我。
为了方便使用XPaths,Scrapy提供XPathSelector 类,有两种可以选择,HtmlXPathSelector(HTML数据解析)和XmlXPathSelector(XML数据解析)。
必须通过一个 Response 对象对他们进行实例化操作。
你会发现Selector对象展示了文档的节点结构。因此,第一个实例化的selector必与根节点或者是整个目录有关 。
在Scrapy里面,Selectors 有四种基础的方法(点击查看API文档):
xpath():返回一系列的selectors,每一个select表示一个xpath参数表达式选择的节点
css():返回一系列的selectors,每一个select表示一个css参数表达式选择的节点
extract():返回一个unicode字符串,为选中的数据
re():返回一串一个unicode字符串,为使用正则表达式抓取出来的内容
3.3xpath实验
下面我们在Shell里面尝试一下Selector的用法。
实验的网址:http://www.dmoz.org/Computers/Programming/Languages/Python/Books/

熟悉完了实验的小白鼠,接下来就是用Shell爬取网页了。
进入到项目的顶层目录,也就是第一层tutorial文件夹下,在cmd中输入:
回车后可以看到如下的内容:

在Shell载入后,你将获得response回应,存储在本地变量 response中。
所以如果你输入response.body,你将会看到response的body部分,也就是抓取到的页面内容:

或者输入response.headers 来查看它的 header部分:

现在就像是一大堆沙子握在手里,里面藏着我们想要的金子,所以下一步,就是用筛子摇两下,把杂质出去,选出关键的内容。
selector就是这样一个筛子。
在旧的版本中,Shell实例化两种selectors,一个是解析HTML的 hxs 变量,一个是解析XML 的 xxs 变量。
而现在的Shell为我们准备好的selector对象,sel,可以根据返回的数据类型自动选择最佳的解析方案(XML or HTML)。
然后我们来捣弄一下!~
要彻底搞清楚这个问题,首先先要知道,抓到的页面到底是个什么样子。
比如,我们要抓取网页的标题,也就是<title>这个标签:

可以输入:
sel.xpath('//title')
结果就是:
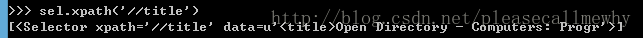
这样就能把这个标签取出来了,用extract()和text()还可以进一步做处理。
备注:简单的罗列一下有用的xpath路径表达式:
表达式 描述
nodename 选取此节点的所有子节点。
/ 从根节点选取。
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
. 选取当前节点。
.. 选取当前节点的父节点。
@ 选取属性。
全部的实验结果如下,In[i]表示第i次实验的输入,Out[i]表示第i次结果的输出(建议大家参照:W3C教程):