python中正则表达式的使用详解(4)
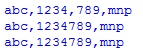
sen = "abc,123,4,789,mnp"
while 1:
mm = re.search("\d,\d", sen)
if mm:
mm = mm.group()
sen = sen.replace(mm, mm.replace(",", ""))
print sen
else:
break
print sen
结果
四. 中文处理之年份转换(例如:一九四九年--->1949年)
中文处理涉及到编码问题。例如下边的程序识别年份(****年)时
# -*- coding: cp936 -*-
import re
m0 = "在一九四九年新中国成立"
m1 = "比一九九零年低百分之五点二"
m2 = '人一九九六年击败俄军,取得实质独立'
def fuc(m):
a = re.findall("[零|一|二|三|四|五|六|七|八|九]+年", m)
if a:
for key in a:
print key
else:
print "NULL"
fuc(m0)
fuc(m1)
fuc(m2)
运行结果

可以看出第二个、第三个都出现了错误。
改进——准化成unicode识别
# -*- coding: cp936 -*-
import re
m0 = "在一九四九年新中国成立"
m1 = "比一九九零年低百分之五点二"
m2 = '人一九九六年击败俄军,取得实质独立'
def fuc(m):
m = m.decode('cp936')
a = re.findall(u"[\u96f6|\u4e00|\u4e8c|\u4e09|\u56db|\u4e94|\u516d|\u4e03|\u516b|\u4e5d]+\u5e74", m)
if a:
for key in a:
print key
else:
print "NULL"
fuc(m0)
fuc(m1)
fuc(m2)
结果

识别出来可以通过替换方式,把汉字替换成数字。
参考
numHash = {}
numHash['零'.decode('utf-8')] = '0'
numHash['一'.decode('utf-8')] = '1'
numHash['二'.decode('utf-8')] = '2'
numHash['三'.decode('utf-8')] = '3'
numHash['四'.decode('utf-8')] = '4'
numHash['五'.decode('utf-8')] = '5'
numHash['六'.decode('utf-8')] = '6'
numHash['七'.decode('utf-8')] = '7'
numHash['八'.decode('utf-8')] = '8'
numHash['九'.decode('utf-8')] = '9'
def change2num(words):
print "words:",words
newword = ''
for key in words:
print key
if key in numHash:
newword += numHash[key]
else:
newword += key
return newword
- 上一篇:Python入门篇之编程习惯与特点
- 下一篇:基于python编写的微博应用